작은 kernel들이 입력 이미지 위를 convolution계산하며 지나가고, classification에 중요한 feature들을 detect한다. 앞단에 있는 convolution들은 선과 같은 단순한 feature를 탐지하고, 뒤로 갈 수록 복잡한 feature들을 탐지한다.
2. BatchNormalization
Input을 normalize하는 것 처럼, batch normalization은 hidden layer의 값들을 스케일링한다.
* Input을 normalize하는 이유: weight, update schedule, step size, 등등 모든 default setting들이 normalized scale [0,1]에 맞추어져 있다. 따라서 [0,1] recommended option으로 learning해야 빠르게 수렴할 수 있다.
낮은 resolution으로 변환시켜준다. Maxpool을 해주면서 모델이 translation(옆으로 shift같은 경우)에 강인하도록 만들고, 더 빠른 연산을 가능하게 한다.
* Translation invariance The output is invariance to the translation of input information. (invariance = does not chance) translation = little bit shift of image. 그림 살짝 옮겨서 input으로 넣어줘도 output은 완전히 같은 것을 의미한다. 이 translation invariance는 cnn에서 max pooling layer에 의해 생긴 중요한 특징이다. (반면 일반 fc layer는 shift하면 output 완전히 다르다)
따라서 translation invariance를 가지는모델의 데이터가 많지 않다면, 단순히 shift시킨 데이터를 추가해줘서 데이터를 증강시켜주는 방법을 사용해도 된다.
4. Dropout
Overfitting을 예방하는 기법이다. Dropout은 뉴런의 일부를 임의로 선택한 후 동작하지 않게 만들어서 특정 pass동안 forward, backward propagation에 참여하지 않게 만든다. 이렇게 하면 네트워크가 robust해지고, 어느 한 뉴런 영역에만 의존하지 않으며 답을 얻을 수 있다.
5. Flatten
Flatten은 다차원인 한 레이어의 출력을 가져와 1차원 배열로 병합한다. 출력은 feature vector라고 하며 최종 분류 계층에 연결된다.
6. Dense
실질적인 classification을 진행하는 레이어이다. 입력으로는 flatten된 feature vector를 받고, 예측값을 출력한다.
Neural network에서 마지막 레이어의 activation function은 ReLU가 아닌 softmax를 사용해야 한다.
Data Augmentation
모델은 validation dataset에 대해서 test를 할 때, 기존 훈련 시 보았던 데이터가 아니기 때문에 혼란을 겪는다. 그래서 종종 training accuracy보다 validation accuracy가 낮게 되고, 이것을 overfitting이라고 부른다.
모델이 새로운 데이터에 대해서 강인하게(robust) 만들기 위한 방법 중 하나가 데이터셋의 크기와 variance를 키워주는 데이터 증강 기법이다.
size 증가: training 양 증가
variance 증가: classification( 또는 다른 task)에 중요한 feature만 선택 & generalize 능력 향상
overfitting = generalize가 잘 되지 않았을 때의 현상.
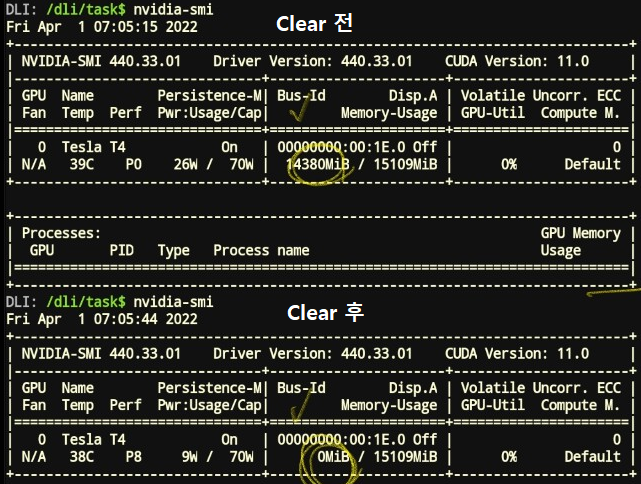
Clear the Memory
학습이 끝나고 다른 작업으로 넘어가기 전에 아래 코드를 사용해서 GPU 메모리를 비워주면 좋다.
GPU 메모리: GPU의 중요한 성능. 학습 시 data를 GPU 메모리로 옮기고 parallel computation 진행한다. Memory가 작다면 data 옮기고 계산하는 작업을 매우 많이 해야한다. 따라서 memory가 GPU의 중요한 performance 중 하나이다.