[논문리뷰] Attention is all you need
2017, NIPS. 이해한것 바탕으로 내맘대로 초간단 정리
Abstract summary
sequence transduction models는 encoder, decoder를 포함하는 복잡한 RNN/CNN에 기초한다.
가장 성능이 좋은 모델은 attention mechanism을 통해 encoder, decoder 연결한다.
여기서 RNN, CNN 제거하고 오로지 attention mechanism에만 기초한 새롭고 간단한 network 구조 제안 : Transformer
RNN 모델은 순차적 특성 때문에 병렬처리를 배제한다.
RNN의 제약사항을 피하고 입출력의 전역 의존성을 이끌기 위해 병렬화가 가능하고 성능이 좋은 Transformer을 제안한다.
Research questions
Recurrence 완전히 없앨 수 없을까?
recurrence가 아닌, 완전히 병렬적으로 sequence 데이터를 처리할 수 있어서 훨신 빠르다.
Dataset
WMT 2014, English-Germen dataset
Model Architecture
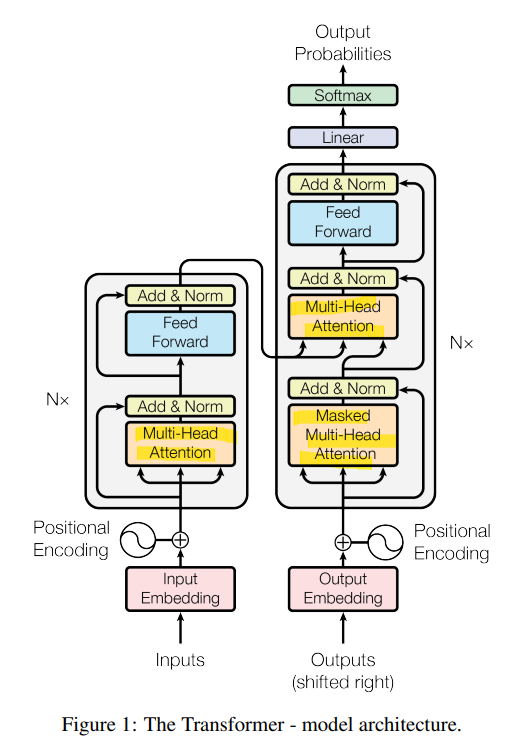
Attention만으로 encoder-decoder 구조.
Transformer는 RNN, CNN을 전혀 필요로 하지 않는다.
Attention 과정을 여러 레이어에서 반복한다. 즉, 인코더 디코더를 N번 중첩.
Attention은 query와 key-value 쌍들을 output에 매핑해주는 함수라고 말할 수 있다.
query, key, value, output은 모두 vector이다.
output은 value들의 weighted sum으로 계산되고, 각 value에 할당된 weight들은 query와 key에 의해 생성된다.



Method used & Algorithm
RNN, CNN 전혀 사용하지 않는다->단어들의 순서 정보를 위해 Positional Encoding 사용한다.
RNN 사용한 방법에서는 문장의 각 토큰에 대해서 반복적으로 입력에 넣어 hidden state 갱신했다. 병렬 처리 힘들었다.
Attention mechanism으로 출력 단어 만들 때 마다 출력 정보 중 어떤 정보가 중요한지에 대한 가중치를 만들어서, 더 효율적으로 출력 만들었다.
Results
트랜스포머는 sequence to sequence를 RNN, CNN 없이 self attention만으로 representation을 통해 구현한 최초의 모델이다. BERT와 같은 향상된 네트워크에서도 이 method를 채택했다.
Open questions
1. 텍스트 이외의 입출력에 대한 문제로도 확장하고, 이미지, 오디오, 비디오와 같은 대규모 입출력을 효율적으로 처리하기 위한 local, restricted attention 매커니즘 연구.
2. Making generation less sequential is another research goals of ours
my note
대부분의 nerual sequence transduction 모델은 encoder-decoder 구조를 가진다.
Input sequence tokens -> (encoder) -> continuous embedding vector -> (decoder) -> ouput sequences