FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence (NIPS 2020), Google Research
https://arxiv.org/abs/2001.07685
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-label
arxiv.org
Abstract
Semi supervised learning(SSL)은 unlabel 데이터를 모델의 성능 향상에 사용할 수 있게 했다. 본 논문에서는 현존하는 SSL을 단순화시키는 알고리즘을 고안했다.
먼저 약하게 augment된 unlabeled 데이터에 수도 레이블을 생성한다. 생성된 레이블들은 모델이 계속해서 높은 confidence를 가진 prediction을 생성할 때만 유지된다.
그 후 모델은 같은 이미지에 대해서 strongly-augmented된 버전의 이미지를 입력해서 수도 레이블을 예측하도록 학습된다. 매우 간단해보이지만 높은 성능을 보였다고 한다.

그런데 수도 레이블링할 모델은 어떻게 학습시켰지? 뒤에서 알아보자
FixMatch
Consistency regularization과 pseudo-labeling 두 가지를 사용한 artificial label을 생성, 즉 SSL 접근법이다.
먼저, artificial label은 weakly-augmented unlabeled 이미지를 기반으로 생성되었고, 이는 같은 이미지의 strongly-augmented version의 학습에서의 target 값으로 사용되었다.
그리고 pseudo-labeling의 방식에 따라서, 모델이 한 클래스에 대해 높은 확률을 할당할 때에만 artificial label을 유지시켰다.
Consistency regularization
SSL 알고리즘에서 중요한 요소이다. 기본 전제는, 레이블이 없는 한 이미지의 다른 버전(transform된!)을 모델에 입력했을 때 같은 예측을 생성해야 한다는 것이다. 이 아이디어는 "Learning with pseudo-ensembles(NIPS 2014)"에서 처음 고안되었고 Temporal ensembling에 의해서 유명해졌다.
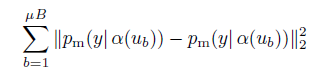
Unlabeled data에 대한 학습은 위 함수로 이루어진다. 단순하게, 두 버전의 input의 예측 값 사이의 MSE를 구하는 것이다. p는 예측값의 distribution을 의미한다.
Pseudo-labeling
모델을 사용해서 레이블이 없는 데이터에 수도 레이블을 만들어주는 아이디어이다. 모델 output의 최대값, 즉 hard label을 사용한다. 미리 정한 threshold를 넘는 가장 큰 클래스 확률을 선택한다. 수도 레이블은 다음 loss funciton으로 생성된다.

qb_hat: argmax(qb). 여기서 argmax는 유효한 one-hot 확률 분포를 출력하는 것이라고 한다! threshold보다 커야하기 때문에 유효라는 개념이 들어간다.
FixMatch
FixMatch에는 두 종류의 cross-entropy term이 포함된다. Supervised loss와 Unsupervised loss이다(ls, lu). 특히 ls는 일반적인 cross entropy loss이다. labeled data에 대한 loss를 구하는데 사용된다.

1. 먼저 weakly-augmented unlabeled image로 모델의 예측값을 생성한다: qb

그리고 가장 큰 레이블을 pseudo label로서 사용한다. output probability에서 가장 높은 확률을 가진 label을 선택한다.
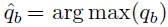
2. qb의 max값이 threshold보다 높다면 unlabeled loss를 계산한다. (consistency loss)

수도 레이블과 strongly-augmented unlabeled image의 예측값 사이에 cross entropy loss를 감마는 수도 레이블을 얻을 threshold를 의미한다. 가장 높은 값을 가진 label이 특정 threshold 확률보다 높을 때 레이블링을 한다.
Indicator function(지시 함수)
위 식에서 1로 보이는 기호는 지시 함수로, 괄호 안의 조건이 만족하면 1, 만족하지 않으면 0을 return한다. 따라서 max(pb)가 r보다 크면 loss 식이 생성되고, 크지 않으면 0으로 loss를 생성하지 않는다는 것을 의미한다.
https://en.wikipedia.org/wiki/Indicator_function
Labeling은 weakly-augmented image를 기반으로, loss는 strongly-augmented image의 output을 기반으로 이루어진다는 것이 차별점이다. 이것이 consistency regularization의 형태를 도입한 것이라고 한다.
따라서 FixMatch의 Loss function은 두 loss의 합으로 결정된다.

Unlabeled data에 대한 loss term의 weight를 훈련이 진행됨에 따라 증가시켜주는 것이 일반적이라고 이전 논문들에서 증명되었다고 한다. 하지만 이건 사용하지 않았다고 .. 훈련이 진행됨에 따라 max(qb)>r의 비율이 자연스레 증가해서 weight 커리큘럼이 없어도 자연스레 이루어졌다고 한다.

Augmentation in FixMatch
- Weak augmentation: flip-and-shift
- Strong augmentation: Cutout, autoaugment(Randaugment, CTAugment)
Related Work: consistency regularization 포함한 SSL 알고리즘들과의 비교

FixMatch는 사실상 Unsupervised Data Augmentation(UDA)와 ReMixMatch의 결합이라고 한다. 두 방법 모두 weakly-augmented example을 사용해서 artificial label을 생성했고, strongly-augmented exmaple을 사용해서 consistency를 강화했다.
다른 점은, 앞선 방법들은 artifical label을 "sharpen" 방식을 사용해서 모델이 높은 confidence의 prediction을 생성하도록 했다는 것이다.
특히 UDA는 predicted class의 가장 높은 확률값이 threshold보다 높을 때만 consistency를 반영했다. FixMatch에서도 이 threshold 아이디어를 사용했다. ReMixMatch에서는 unlabeled loss weight의 annealing을 사용했다.(앞에서 언급했듯 Fixmatch에선 사용하지 않음)
Experiments

CIFAR-10: 4000개의 레이블 데이터, 즉 8%의 레이블 데이터를 사용하는 경우와, 250개 = 0.5%의 레이블 데이터를 사용하는 경우 사이의 error rate 차이가 크지 않았다. 약 0.8% 차이밖에 없었던 점이 흥미로웠다. labeled data 250개면 한 클래스당 25개밖에 되지 않는다는 것인데 ..!
CIFAR-100: 확실히 클래스의 수가 많아지고 유사한 클래스 또한 많아지니 error rate가 크게 증가했다. 10000 label이면 한 클래스당 100개의 데이터인데, CIFAR-10 40 label(4 data per class)와 비교했을 때 큰 차이가 있었다. 필요한 labeled 데이터의 수보다 클래스의 수와 연관성이 더 큰 영향을 미친다는 것을 확인할 수 있다.
CIFAR-100도 클래스당 레이블이 많은 경우에 대한 실험이 있었으면 하는 아쉬움이 있다. semi-supervised의 의미가 떨어지더라도..!
참고로 supervised learning image classification의 SOTA 정확도는 CIFAR10(VIT, 99.5), CIFAR100(EffNet-L2, 96.08)이다.
Strong augmentation은 전반적으로 RA가 CTA보다 좋은 성능을 보였다.

- 추가적인 최적 구조:
lr(Cosine lr decay), Optimizer(momentum SGD.. was better than ADAM!)
Barely Supervised Learning
FixMatch의 한계에 도전하기 위해서 CIFAR-10을 클래스당 하나의 이미지, 즉 10개의 labeled data만 사용해서 적용했다. 두 실험을 설계했다.
1. 서로 다른 10개로 이루어진 4 개의 데이터셋을 만들고, 각 데이터셋들을 네 번에 걸쳐 학습시켰다. test accuracy는 64.28%정도가 나왔다고 한다.


Conclusion
- Labeled, unlabeled data에 standard cross-entropy loss만을 사용해서 적은 양의 코드로도 충분히 구현할 수 있었다.
- 적은 unlabeled data, 심지어 한 클래스당 하나의 데이터만으로도 높은 성능을 보였다.
'DeepLearning' 카테고리의 다른 글
| [논문리뷰] CutPaste: Self-Supervised Learning for Anomaly Detection and Localization (0) | 2022.08.04 |
|---|---|
| [논문리뷰] MixMatch: A Holistic Approach to Semi-Supervised Learning (0) | 2022.07.23 |
| EMA (Exponential Moving Average) 알고리즘 (0) | 2022.07.08 |
| Adagrad->RMSProp, Adam -> AMSGrad (0) | 2022.07.08 |
| Learning Rate Scheduler (0) | 2022.06.21 |