MixMatch: A Holistic Approach to Semi-Supervised Learning (NIPS 2019), Google Research
https://arxiv.org/abs/1905.02249
MixMatch: A Holistic Approach to Semi-Supervised Learning
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm,
arxiv.org
Abstract
Augmented unlabeled 데이터를 사용해서 low-entropy label을 추측하고, labeled와 unlabeled 데이터를 MixUp을 사용해서 섞는다. abstract만 봐서는 어떤 아이디어인지 감이 오지 않는다.
Introduction
Label을 모으는 것은 expert knowledge를 필요로 해서 쉽지 않다. Label 데이터는 private한 정보를 가질 수도 있다. 그래서 unlabeled data를 모으는 것이 훨신 쉽다.
Semi Supervised Learning(SSL)의 사용으로 labeled data의 필요성이 감소했다. 최근의 연구들에서는, unlabeled data에 대한 loss term이 다음과 같은 세 종류 중 하나였다고 한다.
1. Entropy minimization: 모델이 unlabeled 데이터에 대해서 confident한 output prediction을 생성하도록 유도한다.
2. Consistency regularization: 왜곡된 input에 대해서도 모델이 같은 출력 분포를 생성하도록 한다.
3. Generic regularization: 모델이 잘 generalizee되고 training data에 overfit되지 않게 한다.
MixMatch에서는 위 주요 세 접근법들을 하나로 합치는 하나의 unlabeled data loss를 소개한다.
Consistency Regularization
FixMatch에서도 많이 설명해서 넘어간다.
Entropy Minimization
많은 SSL 방법들의 일반적인 가정은, classifier의 decision boundary가 marginal data distribution에서 높은 밀도의 영역을 통과하지 않는다는 것이다.
marginal distribution? 독립 변수, 즉 하나의 변수에 대한 distribution. 예를 들어 컴퓨터 type과 성별에 따른 컴퓨터 가격 선호에 대해 연구를 할 때, 오직 type에 대한 distribution을 알고 싶다고 하자. 이게 marginal distribution이다. 즉, 한 변수 외의 관심 없는 변수들에 대해서는 "marginalize out(소외)"시키는 것이다.
이를 강화하는 방법 중 하나는, unlabeled data에 대해서 classifier가 낮은 entropy의 예측값을 생성하도록 하는 것이다.

Entropy(of random variable)? 쉽게 말하자면 확률변수상 얼마나 무질서/불확실한지에 대한 척도. 무질서도이다. 원래의 정의는 확률분포 p를 binary digits으로 인코딩했을 때 필요한 channel capacity를 의미한다. (by Shannon's definition)


예를 들어, 앞/뒷면이 나올 확률이 같은 동전 던지기의 정보량은 1이다.(0 또는 1) 한 비트만 있으면 동전 던지기의 distribution을 표현할 수 있다는 뜻이다. 만약 앞/뒷면의 확률이 다르다면 더 많은 정보량이 있어야 distribution을 설명할 수 있을 것이다.
동시에 동전의 수가 많아 질 수록, 정보량이 커진다. 즉, 엔트로피가 커진다. 예측하기 어렵고 확률이 낮을 수록 엔트로피가 커진다는 것이다.
따라서 본론으로 돌아가서, 낮은 entropy의 예측값을 생성하도록 한다는 것은 예측하기 쉽도록, 즉 높은 정확도 + 높은 confidence의 예측값을 생성하도록 만든다는 것이다. 단순하게 CEE가 낮다고 이해할 수도 있지만,. 정보 이론 측면에서 한번 더 이해하고 싶어 정리해보았다.
이렇게 낮은 entropy의 예측값으로 stronger result를 생성하는 것이 Entropy Minimization이다. "Pseudo-Label"에서 이 기법을 사용해서 unlabeled data에 대해 high-confidence prediction을 얻어 one-hot labeling을 수행하고, target으로 사용해서 일반적인 CEE를 계산하는 것으로 이어졌다.

MixMatch 또한 unlabeled data의 target distribution에 대해 "sharpening"을 사용해서 entropy Minimization을 도입했다.
Traditional Regularization: weight decay, Mixup
Regularization이란 모델에 제약을 주어서 training data를 기억하는 것을 방해하고, unseen data에 대한 generalization을 강화하는 일반적인 방법이다. MixMatch에서는 L2 norm을 방해하기 위해 weight decay를 사용했고, Labeled/Unlabeled data에 Mixup을 사용해서 데이터들 사이에 convex behavior를 향상시켰다. (convex behavior?)
MixMatch
드디어 본론! Semi-supervised learning method 방법인 MixMatch를 소개한다.
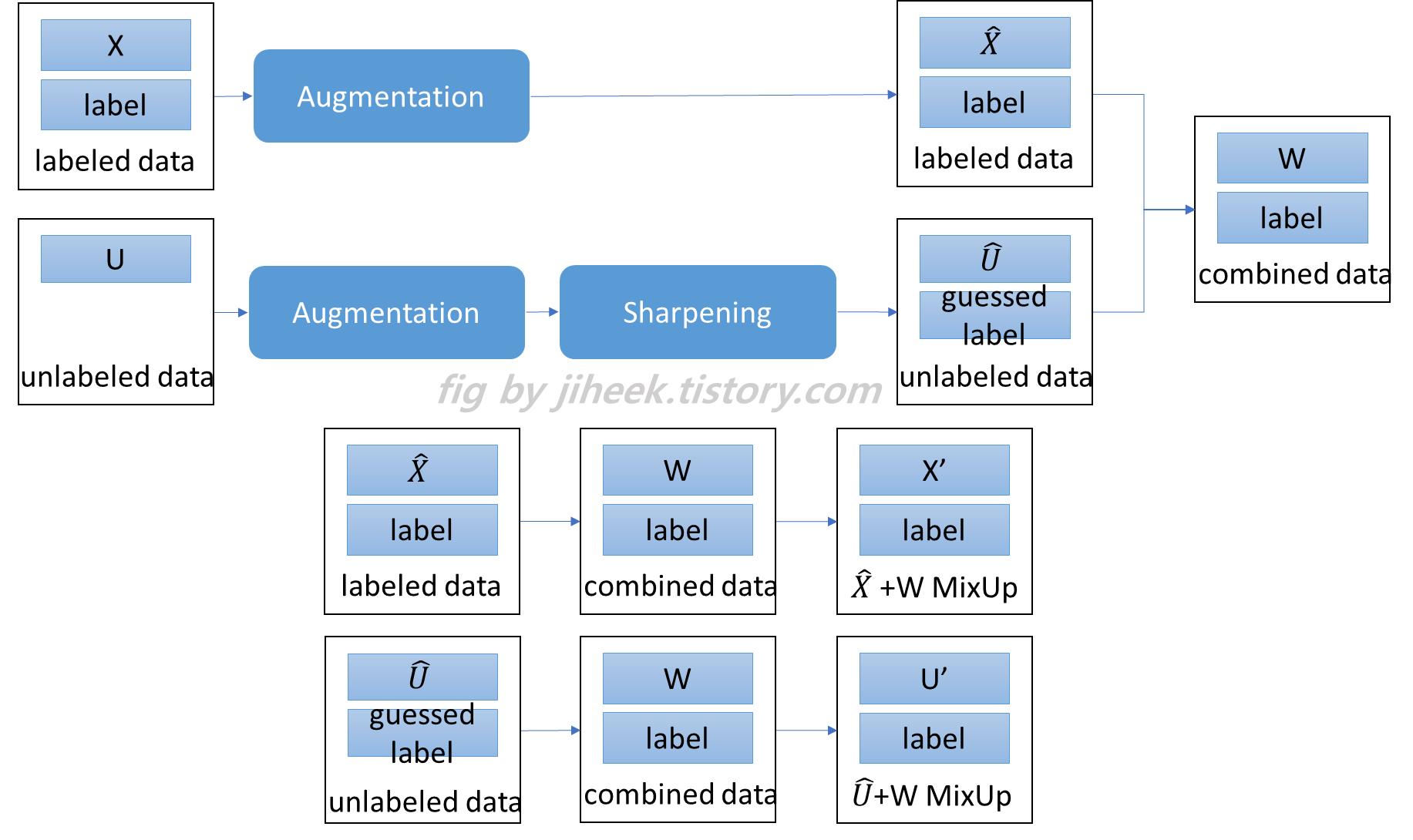
Labeled sample batch인 X와 unlabeled sample batch인 U가 주어졌을 때, 각각 augmented된 batch X'와 U'를 생성한다. (여기서 U'는 guessed label을 가진다고 함(?) 이 label guessing process는 뒤에서 더 자세히 설명한다.) 두 batch들은 labeld와 unlabeled loss를 계산하는데 사용된다.
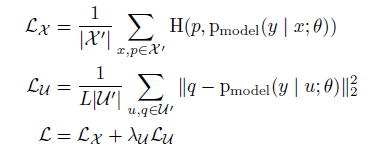
H는 cross entropy를 의미한다.
Label Guessing
Unlabeled sample U에 대해서, MixMatch는 모델의 예측값을 사용해서 예상되는 레이블을 생성한다. 그리고 이 guess는 unsupervised loss를 계산하는데 사용된다. (위 식에서 q에 해당)
이를 위해서 unlabeled data에 대해 K회 이루어진 augmentation들에 대한 예측들의 평균을 계산해야 한다.
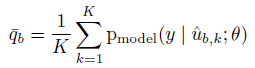
unlabeled 데이터에 대한 가짜 레이블을 얻기 위해서 augmentation을 사용하는 것은 consistency regularization method에서 매우 일반적인 방식이다.
Sharpening
Label guessing을 할 때, Sharpening이라는 추가적인 단계가 더 있다. Augmentation들에 걸친 평균 예측값이 계산되었을 때, label distribution의 entropy를 줄이기 위해서 sharpening function을 사용했다.
Sharpening function으로는 catetorial distribution의 "temperature"'를 조절하는 일반적인 접근법을 사용했다.

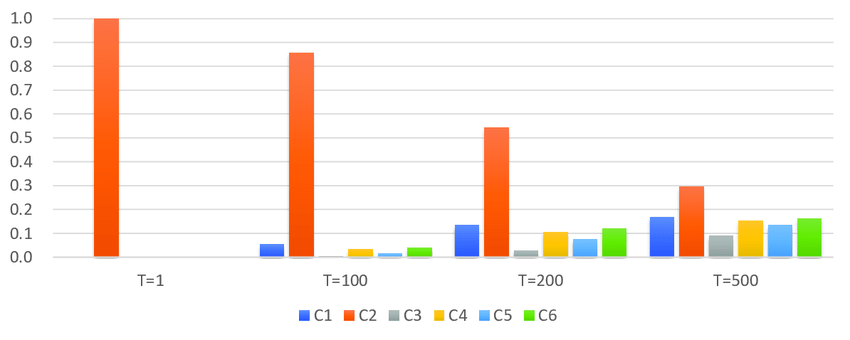
Temperature of Categorial probability distribution
아래 그림에서 C1~C6은 다른 클래스를 의미하고, softmax input logit data는 테이블의 마지막 행에 나열되어 있다. 일반적인 softmax는 T=1인 경우이며, 가장 높은 input logit class의 확률은 1, 나머지는 0을 출력한다. T(temperature)가 높아질 수록 categorial distribution은 큰 차이 없이 일정해진다.

MixUp
Labeled sample과 Unlabeled sample(with guessed labels)을 함께 MixUp을 사용했다. 두 이미지와 label 쌍을 (x1, p1), (x2, p2)라고 하고, MixUp 결과 이미지, label을 (x', p')라고 하자.이 (x', p')는 다음과 같이 계산된다.

vanilla MixUp은 (9)번 식을 제외한다고 한다. 람다'가 없는데, 본 논문에서 새로 도입한 개념이라고 한다. Beta distribution에서 얻은 확률값 람다와, 1-람다 중 더 큰 값을 취해서 MixUp에 사용하였다. 따라서 x'는 x2보다 x1에 더 가깝게 된다. (어디에 더 가깝게 되든 그게 중요한걸까>..?)
알고리즘 수도코드

알고리즘 한줄요약
Unlabeled image(U)에 augmentation + Sharpening 사용해서 label 생성 -> Labeled data(X) + Unlabeled data(+가짜 label)(U) = W 새로운 데이터셋 생성 -> W + X, W + U로 MixUp 진행 및 return
따~라~서~! MixMatch의 목적은 labeled, unlabeled data를 가지고 모두 labeling을 해주고, 그 데이터를 사용해서 mixup을 진행한 데이터셋을 리턴하는 것이다.
"Data->augmentation->pseudo labeling(sharpening)-> MixUp"
Loss Function, Hyperparameters
Return된 데이터셋 X', U'에 대해서는 앞서 설명한 Lx, Lu를 사용한다. 이 때 label과 prediction 사이에는 CEE를 사용하고, prediction과 guessed label U' 사이에는 L2 loss를 사용한다. 또한 guessed label 계산 시에는 back propagation을 사용하지 않았다고 한다.
Temperature T는 0.5, unlabeled augmentation의 개수 K=2로 설정하였다.
Experiments
Implementation details
1. lr decay를 사용하는 대신, parameter EMA (decay of 0.999)를 사용했다.
2. weight decay 0.0004, Wide ResNet-28
3. Baseline model: II-Model , Mean Teacher, Virtual Adversarial Training, and Pseudo-Label

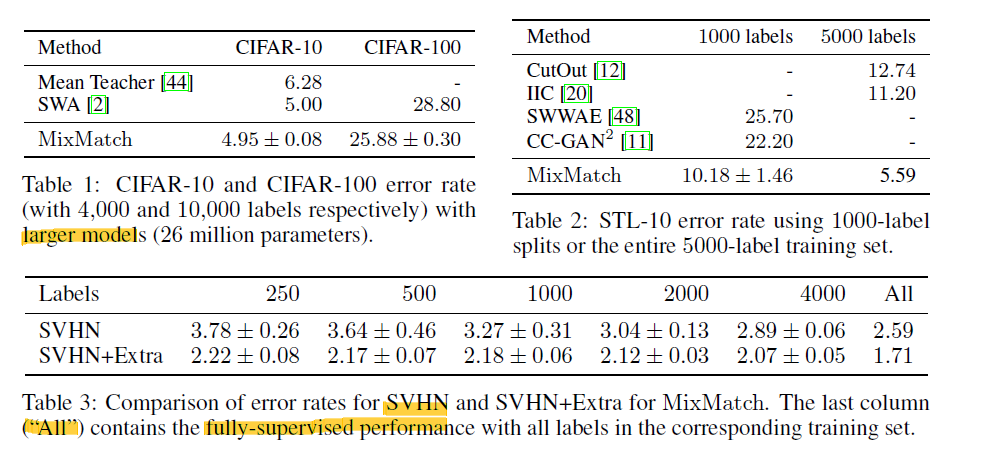
매우 적은(250개) 양의 labeled data만으로도 supervised에 가까운 성능을 보였다.

- Ablation study를 통해, temperature sharpening을 하지 않았을 때 성능이 확연히 줄은 것을 확인했다. Sharpening하는 경우는 T=0.5이고, 사용하지 않았을 때의 T=1이다.
- MixUp을 사용하는 것이 약 27~8% 성능이 더 좋았고, labeled data에만 MixUp을 사용하는 것은 아예 사용하지 않는 것과 큰 차이가 나지 않았다.
- Unlabeled data에 대해서 MixUp을 사용했을 때, 둘 다 사용했을때와 거의 비슷했다.
- EMA의 사용은 드라마틱한 변화는 없었다. 약간의 성능 향상만 있었음
- Augmentation의 개수(K, average 할 개수)도 1개만 아니면 큰 차이는 없었다.
Conclusion
논문의 conclusion은 결국엔 좋았다~였다. 개인적으로 아쉬웠던 점은 ablation study에서 왜 unlabeled only에 MixUp을 적용시켰을 때 드라마틱하게 좋아졌는가에 대한 분석이 없었던 것과, 더 큰 K에 대한 실험의 부재이다.
참고s
'DeepLearning' 카테고리의 다른 글
| Diffusion Model - 개념 알기 (0) | 2022.10.11 |
|---|---|
| [논문리뷰] CutPaste: Self-Supervised Learning for Anomaly Detection and Localization (0) | 2022.08.04 |
| [논문리뷰] FixMatch: simplifying semi supervised learning with consistency and confidence (0) | 2022.07.20 |
| EMA (Exponential Moving Average) 알고리즘 (0) | 2022.07.08 |
| Adagrad->RMSProp, Adam -> AMSGrad (0) | 2022.07.08 |