Keyword: Plasticity, parameter-efficient method
- Abstract
- Pruning pasticity: 프루닝된 네트워크가 원 네트워크의 성능을 회복하는 능력. 이 능력은 brain-inspired 매커니즘인 neuroregeneration, 즉 잘라낸 연결을 regenerate하는 데에 사용해서 향상될 수 있다.
- Pruning method: Gradient magnitude pruning (GMP) method, named zero gradient pruning with zero-cost neuroregeneration (GraNet).
ResNet50 모델에 대해서 다른 dense-to-sparse 방식들보다 본 논문에서의 sparse-to-sparse 방식이 훈련 시간의 증가 없이 sparse 훈련 성능을 높였다.
Post training pruning은 dense network를 pre-train해야 하고, 후에 많은 retrain 과정이 필요하다. 최근의 방식은, 훈련 가능한 subnetwork를 main training process 이전에 정의하는 during-training으로, 더 복잡한 알고리즘을 가지고 아직 full dense training과 성능 차이가 나기 때문에 아직 많은 연구가 되지 않았다.
training 최적화 과정동안 프루닝의 효과를 확인하기 위해서, 현재의 learning rate로 짧은 train 이후 원래 네트워크의 성능을 따라가는 프루닝된 모델의 능력을 연구했다. - 이를 pruning plasticity라고 부른다. 이 아이디어는 신경계의 neuroregeneration 매커니즘에서 따왔다고 한다.. (신경계의 손상된 부분을 회복하기 위해서 새로운 신경 연결이 합성되었는데, 같은 맥락에서 regenerating of new connections이 pruning plasticity를 향상시키고, pruning에 기여할 지 실험해 봄..ㅋ)
- Introduction
본 논문에서의 주요 발견은 다음과 같다. #1~#3
#1. Pruning rate, learning rate 모두 pruning plasticity에 중요하다.
1.1) 높은 pruning rate보단 낮은 (약 0.2) 것이 성능에 좋았다. 하지만 상대적으로 많은 iteration이 필요했다. >>당연!
1.2) 낮은 learning rate는 안좋았고,. 높은 learning rate에서는 처음에는 dense network의 performance를 따라가는 듯 했지만 점점 plasticity가 급격히 떨어지며 회복할 수 없었다. >> 이는 GMP, DST, rewind technique 관측에 대한 설명이 되었다고 함.. 언젠가 추가 논문 찾아봐야 할듯
#2. Neuroregeneration이 pruning plasticity를 향상시켰다.
Neuroregeneeration은 신경계의 뉴론, 셀,.. 등등의 손상에 대한 회복, 합성 매커니즘을 의미한다. 이 컨셉을 가져와서 프루닝된 연결들과 같은 개수의 연결을 regenerate함으로서 pruning plasticity가 눈에 띄게 향상되었다. 하지만 메모리와 계산 오버헤드를 증가시며서 during-training pruning의 장점을 상쇄시킨다. 이런 extra cost 없이 효과적인 neuro어쩌구를 구현할 수 없을까?에 대한 답이 본 논문에 나와있음.
#3. Neuro..를 통한 pruning plasticity를 활용하여 sparse training performance를 크게 높일 수 있다.
새로운 sparse-training method인 GraNet(gradual pruning with zero-cost neuroregeneration)을 제안한다. 그러니까 #2에서 extra cost 없이, 즉, 추가적인 파라미터 없이 효과적인 gradual pruning하겠다는 것을 의미함.
ImageNet, ResNet-50에서 training 시간을 연장하지 않고도 다양한 Dense-to-Sparse 방법에 비해 Sparse-to-Sparse training 성능을 처음으로 향상시켰다고 한다. ==> sparse training from scartch와 비교되는 부분. 해당 논문에서는 훈련 시간을 연장해야 sparse-to-sparse 성능이 더 좋아졌다.
드디어..!
- Methodology for Pruning Plasticity
(1) Metrics

W: wight, m: mask, a: learning rate, t: epoch, CONTRAIN: 프루닝된 모델을 train 시키는 함수. k: 총 epochs
t_constrain: k 에폭 이후 측정된 test accuracy, t_pre: 프루닝 전 측정된 test accuracy.
즉, Plasticity는 프루닝 전과 프루닝 후 (또는 프루닝 도중)의 test accuracy 차이를 뜻한다.
(2) 구조 및 데이터셋

(3) Prune, Regenerate 방법
Structure pruning 방법으로는 [1] 논문에서 사용한 filter pruning 방법을 선택했다. 하지만 더 많은 sparsity와 practical hardware에서의 sparse 연산 지원의 증가로 인해 unstructured pruning이 더 촉망받는 프루닝 방식이다. Unstructured pruning에 대한 예시로는 [2] 논문을 참고하라고 한다.
어쨌든.. 이 논문에서는 weight magnitude pruning, one-shot pruning, Layer-wise pruning/global pruning, gradient-based regeneration 방식을 사용했다.
Gradient-based regeneration: zero weight의 연결을 포함한 gradient는 연결의 중요도에 좋은 방향을 제공한다. 이 regeneration 방식은 [3] 논문에서 처음 제안되었다. 이 방식을 사용해서 프루닝된 연결과 같은 수의 weight를, 큰 gradient를 가진 순서대로 regenerate시킨다.
(4) 실험 결과
ResNet-20, CIFAR-10, unstructured magnitude global pruning의 결과가 메인이다.
1) {0, 0.5, 0.9, 0.98} 네 가지의 sparsity level에서 네트워크를 pre-train시킨다. 이 때 sparse network는 uniform distribution(모든 레이어가 같은 sparsity 가짐) 하에서 train된다.
2) 그리고 {0.2, 0.5, 0.9, 0.98} 네 가지의 pruning rate에서 상응하는 pre-trained 네트워크에 대한 plasticity를 측정한다.
3) pruned model을 30에폭만큼 train시키고 plasticity 측정했다.
결과적으로 learning rate schedule, pruning rate, sparsity of the original model 세 가지 모두 pruning plasticity에 큰 영향을 미쳤다.
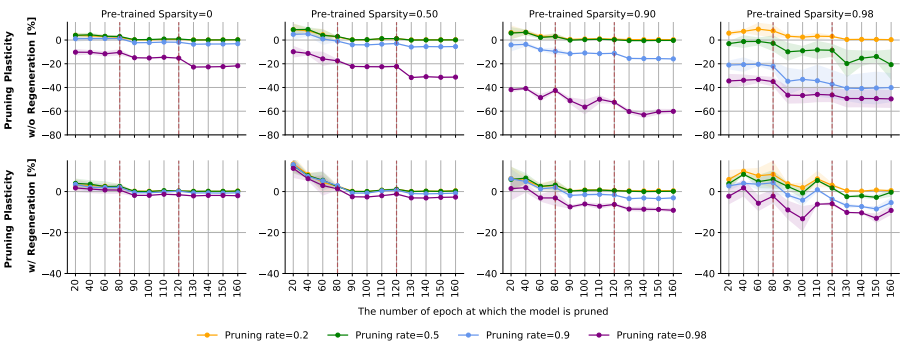
learning rate decay가 있을 때 모든 경우에서 plasticity가 감소했고, pruning rate 0.98 제외하고는 큰 learning rate 0.1에서 원 네트워크와 비슷하거나 더 나은 성능을 보였다. (>>BUT 이건 final performance gap 실험에서 성능이 안좋은 것에서 미루어보아, 원 네트워크가 초기에 불안정해서 그런 것 같다고 추측했다) 또한 connection regeneration이 pruning plasticity를 특히 over-pruned(보라색 선) 모델에 대해서 크게 향상시켰음을 확인할 수 있다.

매우 sparse한 network (3,4열) + mild pruning일 때 좋은 성능 보였다.
역시 regeneration했을 때 좋았다.
- Gradual Pruning with Zero-Cost Neuroregeneration

각 iteration의 프루닝 비율은 위 식에 따라 결정된다. 첫 s0에서는 si의 프루닝 비율을, 마지막 반복에서는 sf의 비율을 갖게 되어서 점점 si에서 sf로 늘어나게 된다. 이 gradual pruning 스케쥴과 global pruning 기법을 사용했다.
기존 gradual pruning 방식에서는 weight가 아닌 마스크만 업데이트하여, 중요한 연결을 재생성(regenerate)하는 데에 방해가 되었다. prunned connection의 weight가 업데이트되지 않는다는 뜻은 pruning threshold를 넘을 충분한 기회가 주어지지 않는다는 뜻이기 때문이다.
- si=0: dense-to-sparse, si>0: sparse-to-sparse
GraNet과 기존의 GMP(gradual magnitude pruning)의 가장 큰 차이점은 Zero-Cost Neuroregeneration이다.
먼저 (1) damaged connection = 가장 작은 크기의 weight를 제거한다. (2) 제거한 connection과 같은 수의 연결을 재생성한다. 이 때 regeneration을 위한 importance score으로는 gradient를 사용한다.
- (1)에서, 작은 크기의 weight는, weight의 gradient의 크기가 작거나 gradient 도중 많은 진동이 발생하여 training loss에 많이 기여하지 못하며, 제거될 수 있음을 의미한다.
- (2)의 방법은 RigL[4]의 방법과 같다고 한다.
왜 Zero-Cost Neuroregeneration이라고 부르는가?
conncection(weight)의 수를 늘리지 않는 것 뿐만 아니라, regeneration에서 중요한 연결을 식별하기 위해 dense gradient를 사용하더라도 본 논문 방식의 backward pass는 대부분 sparse하다. >> 어케알아?
각 gradual pruning step 직후 바로 neuroregeneration을 진행했다.
기존 방식은 backward pass의 모든 weight를 업데이트해야 했지만, 본 방식에서는 더 효율적이게 2/3 정도의 훈련 FLOPs만 backward pass에 사용해도 됐다.
- FLOPs 참고: https://hongl.tistory.com/31
FLOPS (FLoating point OPerationS) - 플롭스
개발한 딥러닝 모델은 얼마나 빠를까요? 특히, 모바일 같은 저사양 디바이스에서의 딥 뉴럴 네트워크에서는 성능보다는 해당 사양에서 원활히 돌아가는지가 서비스 측면에서 매우 중요합니다.
hongl.tistory.com
위 neuroregeneration 방식을 수식으로 정리하면 아래와 같다.
먼저, TopK(a,b)는 v로부터 상위 k 비율만 남긴 weight tensor를 리턴하는 함수이다.
(1) r 비율의 작은 값 가진 damaged weight 제거

(2) gradient magnitude 기반으로 r 비율의 weight 재생성

- 실험 결과

GraNet initial sparsity 0.5, target pruning ratio 80%일 때 dense와 거의 동일한 test accuracy 나타냈다.
본 논문에서는 si=0/0.5, t0=0, tf=30을 사용했다.

위 표에서 FLOPs는 dense model의 것으로 normalize되었다. 위 표에서 볼 수 있듯이 작은 초기 sparstiy에서 더 나은 final sparsity distribution을 찾을 수 있고, 더 작은 FLOPs에서 높은 정확도를 냈다. 낮은 feedforward FLOPs가 denser initial network로부터 야기된 오버헤드와 균형이 맞추어진다.
또한 train FLOPs는 si에 robust함을 볼 수 있다.
결론
- Durning-training pruning을 pruning plasticity의 관점에서 접근했다.
- GraNet을 통해 dense-to-sparse (si=0), sparse-to-sparse (si>0) 시나리오를 자연스럽게 생성할 수 있었다.
- 훈련 과정동안 sparsity가 고정되어있는 이전 sparse-to-sparse 논문들과 다르게, GraNet에서는 조금 더 dense한 network에서 출발하여 점진적으로 pruning + global pruning하여 원하는 sparsity까지 적은 FLOPs로 도달했다. -- dense한 출발이 GraNet 성공의 키포인트였다.
- 첫 conv layer부터 마지막 fc layer까지 모두 sparsify할 수 있었다.
[1] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf. Pruning filters for efficient convnets. International Conference on Learning Representations, 2016.
[2] S. Liu, D. C. Mocanu, A. R. R. Matavalam, Y. Pei, and M. Pechenizkiy. Sparse evolutionary deep learning with over one million artificial neurons on commodity hardware. Neural Computing and Applications, 33(7):2589–2604, 2021.
[3] U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen. Rigging the lottery: Making all tickets winners. In International Conference on Machine Learning, pages 2943–2952. PMLR, 2020.
[4] U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen. Rigging the lottery: Making all tickets
winners. In International Conference on Machine Learning, pages 2943–2952. PMLR, 2020.
'DeepLearning' 카테고리의 다른 글
| [논문리뷰] Autoaugmentation (2019/04) (0) | 2022.04.11 |
|---|---|
| [논문리뷰] Auto-Encoding Variational Bayes - VAE (0) | 2022.02.08 |
| [경량화] Pruning 프루닝 (0) | 2022.01.20 |
| Deep Learning - CH3.1 Probability and Information Theory (0) | 2021.10.24 |
| Naive Bayesian Classifier (0) | 2021.10.15 |