AutoAugment: Learning Augmentation Strategies from Data
2019/04, Ekin D. Cubuk et al. (Google Brain)
https://arxiv.org/abs/1805.09501
AutoAugment: Learning Augmentation Policies from Data
Data augmentation is an effective technique for improving the accuracy of modern image classifiers. However, current data augmentation implementations are manually designed. In this paper, we describe a simple procedure called AutoAugment to automatically
arxiv.org
- 강화학습을 사용해서 최적의 augmentation 조합을 찾아주는 알고리즘이다.
Abstract
Minibatch마다 각 이미지에 랜덤으로 골라진 sub-policies 찾는 search space design.
이 때 sub-policies: 두 개의 image processing functions으로 이루어짐.
Search Algorithm 목적: 가장 높은 val accuracy를 보이는 policy 찾는다.
Introduction
Data augmentation은 랜덤으로 augment하여 데이터의 다양성, 양을 늘려주는 테크닉이다.
또한 data domain에서 모델이 invariance(불변성)하다는 것을 가르치는 데에도 사용된다.
잠재적인 불변성을 통합하기 위해 데이터 증대를 사용하는 것이 불변성을 모델 아키텍처에 직접 하드코딩하는 것보다 쉬울 수 있다.
*사용한 Search Algorithm: Reinforcement Learning
아래 두 케이스에서 좋았다.
- Autoaugment가 data에 직접 적용되어 가장 좋은 policy 찾는 경우 (direct application)
- 학습된 policy들은 새로운 데이터셋으로 전이될 수 있었다. -> 1번이 expensive한 경우 대안이 됨
다른 데이터셋에서(e.g. ImageNet->FGVC) transferred policy를 사용해도 잘됐음. 데이터셋과 모델이 달라도 일반화가 잘 되었다.
ImageNet pretrained + 다른 데이터셋 fine tuning보다 ImageNet policy로 학습시킨 test acc 결과가 더 좋았다. (- 이 결과가 data aug policies를 전이하는 것이 기존의 weight transfer learning의 대안이 될 수 있겠다고 제안함)
Related Work
이전까지는 dataset-specific한 augmentation method가 채택되었다. -> 시간오래걸림
BUT Autoaugment는 어떤 데이터셋에도 사용할 수 있음. -> motivation
데이터로부터 data augmentation policies 찾는 것이 이 논문의 목적.
Architecture search (데이터로부터 모델 구조 찾기 위해 reinforcement learning 사용함)에서 영감을 얻었다. But architecture search만으로는 CIFAR-10에 대해서 error rate 2%의 장벽을 넘지 못했다.
- Related work 요약
- Smart Augmentation: 같은 클래스에서 여러 샘플을 합쳐서 자동으로 증강 데이터 생성하는 네트워크
- Tran et al: training set으로부터 대운 distribution을 기반으로 Bayesian approach을 사용해서 데이터 생성
- DeVries and Taylor: 학습된 feature space -> augment data로 간단한 변환
- GAN: augmented data를 바로 생성함. 반면 Autoaug는 operations만 생성.
AutoAugment: Searching for best Augmentation policies Directly on the Dataset
Discrete search problem으로 best aug policy 찾자!
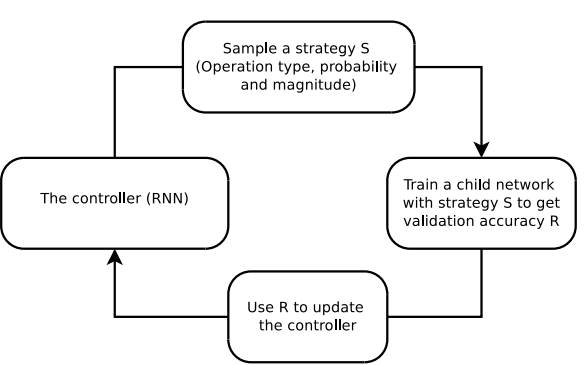
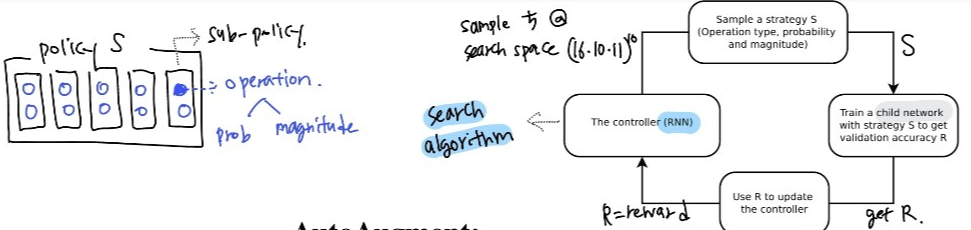
Figure 1: S 샘플링 -> R 얻기 위해 S를 사용해서 network 훈련 -> R으로 controller 업데이트 -> controller -> … 반복
- 두 구성요소: search algorithm(controller RNN), search space
크게 보면 search algorithm은 데이터 증강 policy S를 샘플링한다.
S: 어떤 이미지 처리 operation을 사용할 지, 각 배치에서 operation을 사용할 확률, operation의 크기에 대한 정보를 담고 있다.
- Key point: policy S는 고정된 구조의 nn 훈련시키는데 사용되고, 이 nn 모델의 val acc R은 controller 업데이트에 사용된다.
- R은 미분 불가하기에 policy gradient method를 사용해서 controller 업데이트
두 구성요소에 대한 자세한 설명 - Search space, algorithm
1. Search Space details
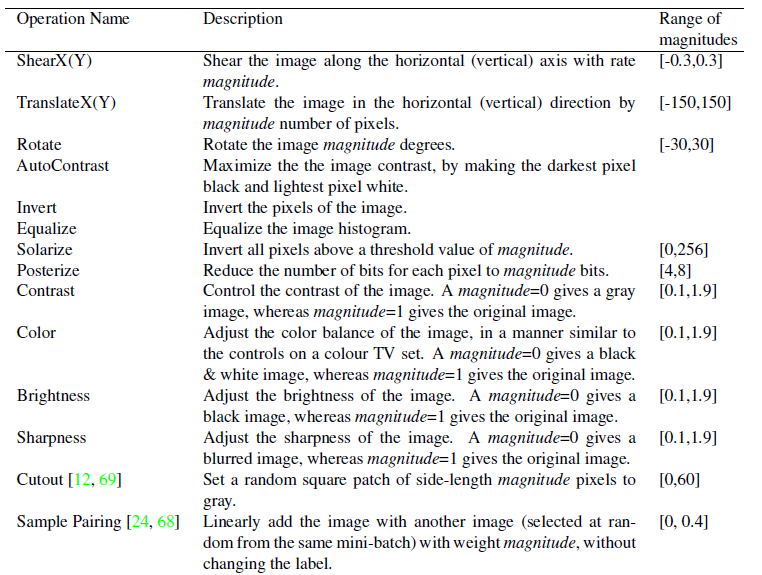
Policy는 5 개의 sub-policy로 이루어져있고, 각 sub-policy는 차례대로 이미지에 적용될 두 개의 sequential한 operation으로 구성되어 있다. 그리고 operation에는 두 개의 hyperparameter: (1) operation 적용할 확률, (2) operation 크기; 로 이루어져 있다. 예시 Fig2 참고.

operation은 PIL (python image library) + Cutout, Sampleparing 사용. Total 16
PIL: ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness
Magnitude는 10 개의 uniform 간격을 가진 값, probability는 11개의 값으로 나누어서 (discretize) discrete search algorithm을 사용할 수 있도록 만들었다.
-> 따라서 하나의 sub-policy를 찾는 것은 (16*10*11)^2 경우의 수를 가진다.
-> 우리의 목표는 diversity를 높이기 위해 5 개의 sub-policies 찾는 것이기에 (16*10*11)^10 = 대략 2.9*10^32 가지의 경우의 수가 있다.
2. Search Algorithm details
Reinforcement learning을 algorithm으로 사용했다.
search algorithm은 두 구성요소로 이루어져 있다: (1) controller(RNN)과 (2) training algorithm (Proximal Policy Optimization algorithm)
각 step에서, controller는 softmax에 의한 decision을 만들어낸다. 이 decision=예측은 다음 스텝에 임베딩으로 들어간다. 이 때 controller는 5 개의 sub policies를 예측하기 위해서 30개의 softmax값을 출력한다.(5 sub policies * 2 operations * 3 (operation type, probability, magnitude)
-> search space와 algorithm에 대한 대략적인 내용 훑었다. 이젠 훈련/구조에 대한 설명.
3. The training of controller RNN
Controller는 “child model”의 generalization을 얼마나 잘 향상시키냐!를 의미하는 reward signal으로 학습된다.
얼마나 잘 향상시키냐의 척도는 validation accuracy를 사용.
즉, reward signal == val acc == RNN controller 학습시키는 값
Child model은 5 sub policies를 training set에 적용해서 증강된 데이터를 사용해서 훈련된다. 각 mini-batch에서 5 policies 중 하나를 랜덤으로 선택하여 증강시킨다.
실험에서 각 데이터셋마다 controller는 15000개의 policy들을 샘플링한다.
4. Architecture of controller RNN and training hyper-parameters
Controller를 위한 학습 절차와 hyperparameter들은 [72]논문에서 가져왔다.
- Controller RNN: one-layer LSTM with 100 hidden units at each layer, 두 convolutional cell에 대해서 2*5B개의 softmax prediction (B는 주로 5)을 가진다.
10B prediction 확률들의 합 == joint probablility of child network
이 joint probability는 controller RNN을 위한 gradient 계산에 사용된다.
Controller가 [안좋은 child net에게는 낮은 확률을, 좋은 child net에는 높은 확률]을 할당하도록 만들기 위해 child net의 val acc에 의해 gradient가 스케일링된다.
Search 마지막에는 best 5 policies의 25개 sub policies들을 single policy로 병합(concatenate)한다. 이 25개 sub policy로 이루어진 final policy는 모델을 훈련시키는 데에 사용된다.
Experiments and Results
- Searching process동안 child nets 학습 시간 줄이기 위해 CIFAR-10 50000 데이터 중 4000개만 사용한, reduced CIFAR-10 사용. (최종 policy와 데이터 수 사이에 관계 없어보인다고 함).
- 찾은 policy로 full CIFAR-10에 대한 final model 학습.
- Child net은 ResNet-40-2(widening factor 2), 120 epochs으로 학습.
- Weight decay 10^-4, lr 0.01, cosine learning decay.
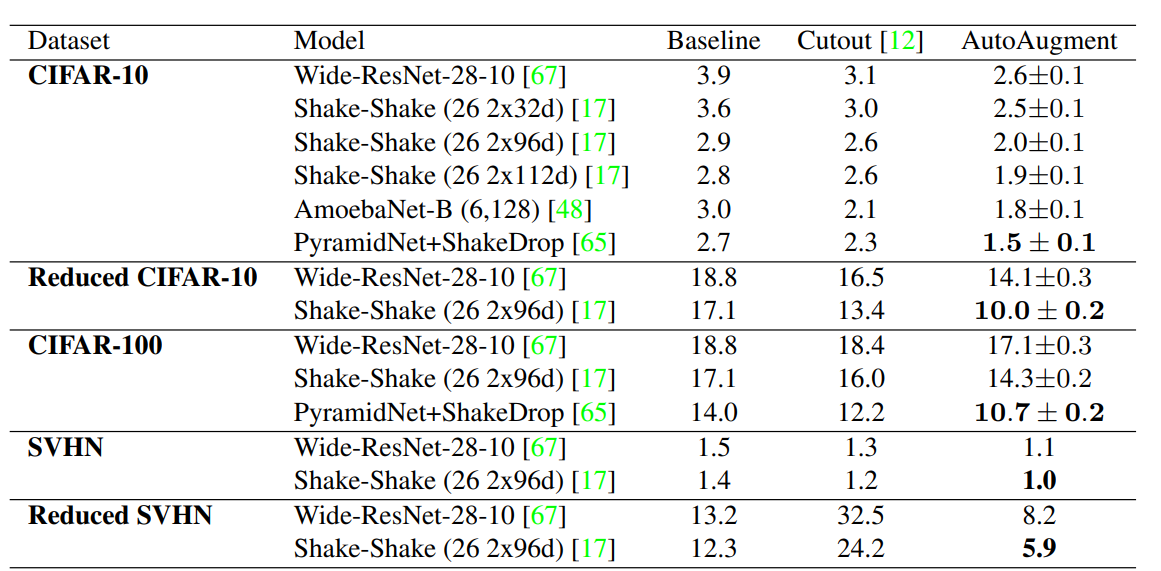
Supplementary materials

github 코드들을 찾아보면, 논문에서 위 표와 같이 이미 search한 25개의 결과 policy를 가지고 CIFAR, ImageNet 등.. 에 대해서 train을 구현한 것이 많다.
<정리>
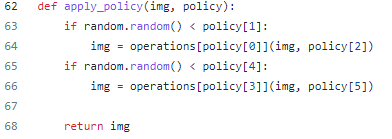
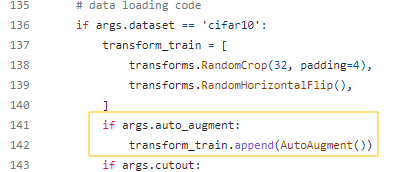
Github 예시 (이미 search한 policy 사용)
https://github.com/4uiiurz1/pytorch-auto-augment/blob/master/auto_augment.py

'DeepLearning' 카테고리의 다른 글
| 딥러닝 데이터셋: Mnist, SVHN, CIFAR, ImageNet (0) | 2022.04.11 |
|---|---|
| RNN, LSTM 간단한 설명 (0) | 2022.04.11 |
| [논문리뷰] Auto-Encoding Variational Bayes - VAE (0) | 2022.02.08 |
| [경량화] sparse training via boosting pruning plasticity with Neuroregeneration 리뷰 (0) | 2022.01.26 |
| [경량화] Pruning 프루닝 (0) | 2022.01.20 |