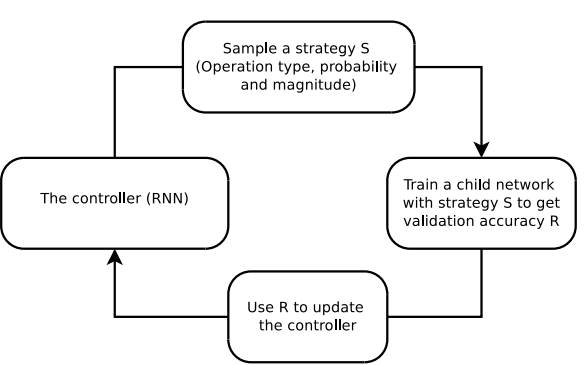
RNN(Recurrent Neural Network) Hidden state: Representation of previous input. Loop! 이전 input의 상태를 기억하고 있는다. Sequential memory인 RNN으로 sequential pattern 더 잘 이해 가능하다. 챗봇의 경우, RNN을 사용해서 input sequence of text를 인코드한다. 임베딩된 RNN 출력을 fc layer에 입력해서 classify 또는 다른 task를 수행한다. But, nature of back propagation algorithm인 short term memory & vanishing gradient 때문에 앞의 단어들(what, time)은 점점 비율이 사라진다. 첫부분의 weigh..